
”hadoop mapreduce“ 的搜索结果

:ApacheHadoop是目前分析分布式数据的首选工具,和大多数Java?2.0技术一样,是可扩展的。从Hadoop的MapReduce编程建模开始,学习如何用它来分析数据,满足大大小小的商业信息需求。Google在2001年发布图像搜索功能...
概要 目标是学习 Apache(大)数据库框架 - Hadoop、Pig、Hive、Hbase 描述 目前在 2 个数据集上有 3 个项目: 百万歌曲数据集 Most_Popular_Genres :使用非常简单的流派识别(Apache Hive 与 Apache Pig)确定...
1.背景介绍 1. 背景介绍 Apache Spark和Hadoop MapReduce都是大规模数据处理领域的重要技术。Spark是一个快速、高效的大数据处理框架,它可以处理批处理和流处理任务。Hadoop MapReduce则是一个分布式计算框架,它...
一般来说,基于Hadoop的MapReduce框架来处理数据,主要是面向海量大数据,对于这类数据,Hadoop能够使其真正发挥其能力。对于海量小文件,不是说不能使用Hadoop来处理,只不过直接进行处理效率不会高,而且海量的小...
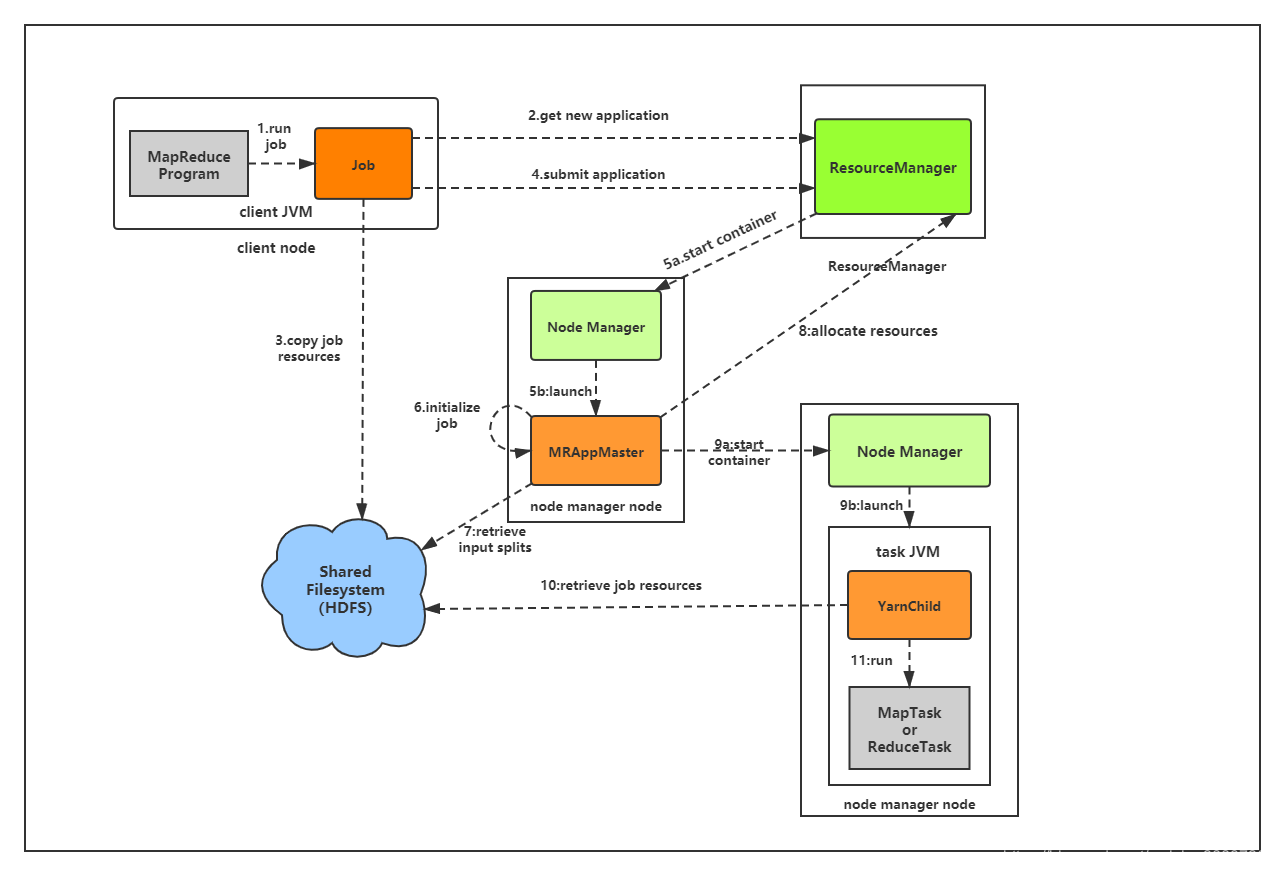
MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是"任务的分解与结果的汇总"。...
HadoopMapReduce作业有着独一无二的代码架构,这种代码架构拥有特定的模板和结构。这样的架构会给测试驱动开发和单元测试带来一些麻烦。这篇文章是运用MRUnit,Mockito和PowerMock的真实范例。我会介绍1.使用MRUnit...
在HDFS上存储文件,大量的小文件是非常消耗NameNode内存的,因为每个文件都会分配一个文件描述符,NameNode需要在启动的时候加载全部文件的描述信息,所以文件越多,对NameNode来说开销越大。假如成百上千的小文件...
其实,使用MapReduce计算最大值的问题,和Hadoop自带的WordCount的程序没什么区别,不过在Reducer中一个是求最大值,一个是做累加,本质一样,比较简单。下面我们结合一个例子来实现。我们通过自己的模拟程序,生成...
net连接hadoopMapreduce驱动(MapRHiveODBC64)net连接hadoopMapreduce驱动(MapRHiveODBC64)net连接hadoopMapreduce驱动(MapRHiveODBC64)net连接hadoopMapreduce驱动(MapRHiveODBC64)net连接hadoopMapreduce驱动...
人工智能-hadoop
Spark与HadoopMapReduce是大数据处理领域中两种非常重要的技术。Spark是一个快速、灵活的大数据处理框架,可以处理批处理和流处理任务。HadoopMapReduce则是一个基于Hadoop生态系统的大数据处理框架,主要用于批处理...
内容概要: HadoopMapReduce-分区、排序、切片实现Java源代码; HadoopMapReduce-分区、排序、切片的原理,流程,分析,笔记等等
本文是Hadoop最佳实践系列第二篇,上一篇为《Hadoop管理员的十个最佳实践》。MapRuduce开发对于大多数程序员都会觉得略显复杂,运行一个WordCount(Hadoop中helloword程序)不仅要熟悉MapRuduce模型,还要了解Linux...
MapReduce是用于数据处理的一种编程模型,简单但足够强大,专门为并行处理大数据而设计。MapReduce的处理过程分为两个步骤:map和reduce。每个阶段的输入输出都是key-value的形式,key和value的类型可以自行指定。...
HadoopMapReduce 输出在输入文件“vanrikki-stool.txt”的输入中出现至少 100 次的单词- 前两个命令用于格式化 HDFS 和启动 Hadoop。 - 然后创建“输入”目录并将“vanrikki-stool.txt”输入文件放入其中。 - 编译后...
HadoopMapReduce教程.pdf
Map/Reduce是一个用于大规模数据处理的分布式计算模型,它最初是由Google工程师设计并实现的,Google已经将它完整的MapReduce论文公开发布了。其中对它的定义是,Map/Reduce是一个编程模型(programmingmodel),是...
hadoopMapReduce实例解析.pdf
HadoopMapReduce Hadoop MapReduce 示例
新手学习并实践的简单mapreduce小项目
大数据 发布大数据仓库 Simple BigData Concepts
OpenStack与Hadoop被誉为继Linux之后最有可能获得巨大成功的开源项目。这二者如何结合成为更猛的新方案?业内给出两种答案:Hadoop跑在OpenStack上或OpenStack部署到Hadoop上。SteveMarkey教授重点介绍了后者。...
HaddopMapReduce 奇怪的人hadoop MapReduce程序
使用Hadoop进行Map Reduce 马其顿大学希腊大数据课程团队项目 处理数据集,其中包含城市居民的个人数据。 目标是找到公民,其数据在数据集中存在多次,并删除所有重复项。 为了实现前者,还使用了Apache Hadoop和...
指示: 步骤1:启动python脚本以对书进行索引,将创建一个文件GutenbergBook.csv-python create_doc_index.py book,其中book是包含所有包含txt文件的目录'etextXY'的目录。 请注意,我已经手动处理了这些目录以删除...
hadoop-MapReduce #Template减少边数据联接欺诈客户检测
频繁项集挖掘 输入:参见文件“数据/数据集”。 输入格式为...> 文件名、文件分割数、支持百分比输出:示例输出在“Data/final.out”中给出 注意:您将需要 hadoop 集群才能执行代码
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地